 ..
..TILED ATTENTION: FLASHATTENTION 1 to 2
You don’t really understand something until you play with it. Reimplementing FlashAttention pushed me to apply concepts from PMPP that otherwise stay abstract: like memory hierarchy, tiling, synchronization and kernel fusion.
Here I walk through both FlashAttention papers and explain the key differences between them.
ATTENTION BRIEFLY
Before getting into FlashAttention itself, it’s worth recalling briefly what attention actually computes. If you are not familiar with attention, I recommend reading Attention Is All You Need first.
>IN ONE ASCII
For a single query q, attention compares it against a set of keys K and uses the result to combine corresponding values V.
K0 K1 K2 ... Kn (keys)
| | | |
v v v v
q (query) -> q·K0 q·K1 q·K2 ... q·Kn
[ softmax ]
|
v
w0*V0 + w1*V1 + w2*V2 + ... + wn*Vn (values)
Here Q is the query, K are the keys and V are the values. Each query produces its own softmax distribution over all keys. Softmax is applied per query. So computing the output for a single query requires scanning all keys to compute dot products, tracking global statistics for numerical stability and then scanning all values again to form the weighted sum.
On a GPU, the computation itself is fine. The real cost comes from memory traffic and synchronization.K and V are repeatedly from global memory while global statistics (max and sum) must be maintained.
SLOW ON GPU
The problem is not compute, it’s memory.
Standard attention writes the N×N attention matrix to HBM, reads it back for softmax, then reads it again to apply V. This moves a huge amount of data through slow memory.
Softmax also requires global reductions, which prevents simple tiling and adds synchronization. Then attention is memory-bound. FLOPs are cheap, memory traffic is not.
So FlashAttention is designed to : reduce memory movement while computing a stable softmax in a single fused kernel.
FLASHATTENTION 1
The core idea is to never write the full N×N attention matrix. Instead, compute it in small blocks that fit entirely in fast on-chip memory.
To understand why this matters, look at this beautiful figure i colored in pink and more specially at the memory hierarchy.
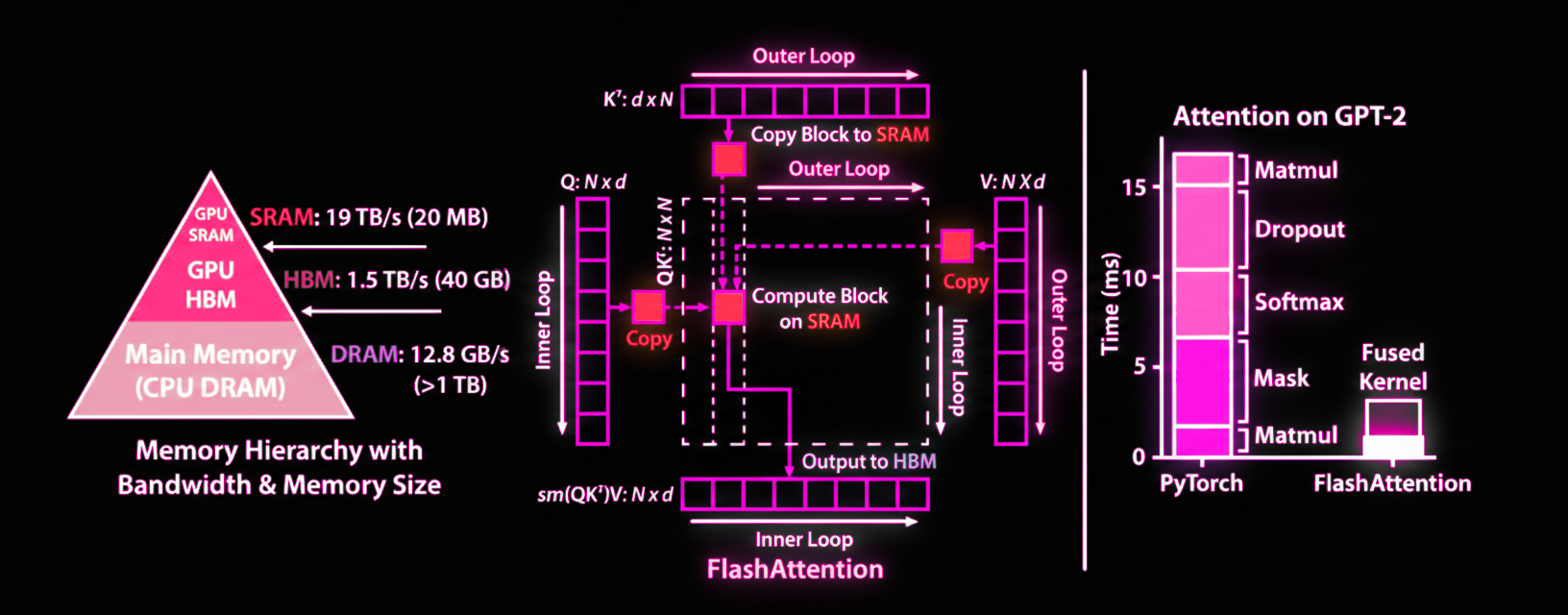
SRAM runs at 19 TB/s but has only 20 MB. HBM runs at 1.5 TB/s with 40 GB—it’s 10× slower but much larger. Standard attention writes the N×N matrix to HBM repeatedly. FlashAttention keeps the computation in SRAM.
>TILING ALGO
Now if we look at center of the figure, we can see how the tiling works. FlashAttention breaks the large Q, K, V matrices into smaller blocks (tiles) that do fit into fast SRAM. It uses two nested loops: the outer loop iterates over blocks of K and V, the inner loop iterates over blocks of Q. For each block combination, compute attention entirely on-chip and update the output.
All operations (matrix multiply, masking, softmax, dropout) happen in SRAM. The N×N attention matrix never gets written to HBM.
BUT HOW DOES THIS WORK WITH SOFTMAX?
Softmax is applied per query and depends on all keys at once. To normalize correctly, you need the maximum score and the sum of exponentials over the full attention row. That’s why FlashAttention uses an online softmax: instead of computing the softmax in one pass over all keys, the algorithm processes key blocks incrementally while maintaining two running values for each query: the current maximum score and the current sum of exponentials. When a new block of keys is processed, these statistics are updated, and previously accumulated values are rescaled if needed.
In my code, for example, you can see this through the per-query variables m and l, which track the running max and sum of exponentials across key blocks.
This online softmax produces the exact same result as a standard one, just the order in which the computation is performed changes.
>KERNEL FUSION & RECOMPUTATION
Because all intermediate values stay on-chip, FlashAttention fuses the entire attention computation into a ** single kernel**. This avoids repeated kernel launches and unnecessary synchronization between stages.
During the backward pass, it does not store the attention matrix either. Instead, attention scores are recomputed on the way using the same tiling strategy as in the forward pass. This trades extra computation for much lower memory traffic, which is a kinda nice trade-off for modern GPUs.
FLASHATTENTION 2
When you first hear about FlashAttention-2, you expect a big algorithmic change. There isn’t one.
FlashAttention-2 computes the same thing as FlashAttention-1, with the same tiling and the same online softmax. The difference is not in the math but in how the computation is scheduled on the GPU.
>LOOP REORDERING
The key change in FlashAttention-2 is a reordering of the loops.
FlashAttention-1 uses outer loop over K/V blocks, inner loop over Q blocks. This means each Q block’s output gets updated multiple times, once per K/V block causing scattered writes to HBM.
To fix this, FA2 uses outer loop over Q blocks and inner loop over K/V blocks. Each Q block is loaded once, processed against all K/V blocks while staying in SRAM, and written once when done.
So we have sequential writes instead of scattered writes. GPUs coalesce sequential memory accesses into larger and more efficient transactions. It’s the difference between writing to consecutive addresses VS jumping around randomly.
>PARALLELIZATION
Reordering the loops also lets you parallelize better.
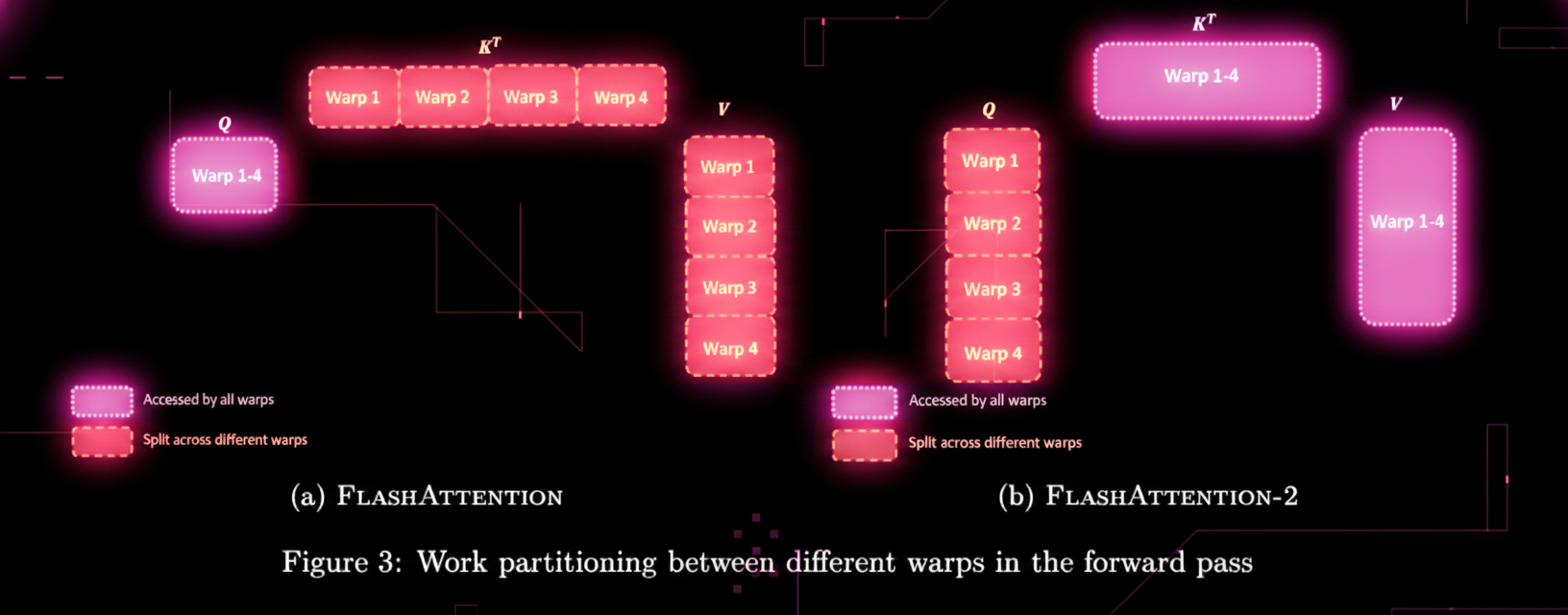
Look at this other beautiful figure from the paper showing work partitioning between warps. In FA1 (left), KT is split across different warps horizontally while Q & V are accessed by all warps. Parallelism happens mostly across heads and batches. One attention head per thread block means low GPU utilization, especially for long sequences with small batches.. This can lead to low occupancy specially for long sequences and small batch sizes.
FA2 (right) changes this completely. Now Q is split across warps vertically while KT and V are accessed by all warps. Multiple thread blocks can now cooperate on the same attention head, each handling different Q blocks. More occupancy and keeps more SMs busy, allowing the kernel to better saturate the GPU!!
No algorithmic change but a good re-factoring around GPU execution.
FlashAttention-2 computes exactly the same attention as FlashAttention-1, the speedup comes entirely from better GPU scheduling.
Playing with attention kernels made me realize how much performance comes from these low-level choices. That’s why this whole attention kernel topic interests me, i want to explore megakernel attention next hehe.
—
LINK:
